本文共 2551 字,大约阅读时间需要 8 分钟。
什么是 Azure Databricks?
Azure Databricks是一个完全托管的、基于云的大数据分析和机器学习平台,通过简化搭建企业级生产环境数据应用程序的流程,使开发人员能够加速导入数据智能和应用创新。Azure Databricks是由Apache Spark的创始团队和微软共同打造的,它为数据科学和数据工程团队提供了一个用于大数据处理和机器学习的统一平台。
通过将Databricks的强大功能与微软Azure平台的企业级和安全性相结合,Azure Databricks简化了大规模Spark工作负载的运营。Databricks是一款端到端的、可管理的、针对云优化的Apache Spark平台。Azure Databricks提供了一个交互式工作区,支撑数据工程师、数据科学家和机器学习工程师之间的协作。Azure Databricks 系统架构如下图所示:
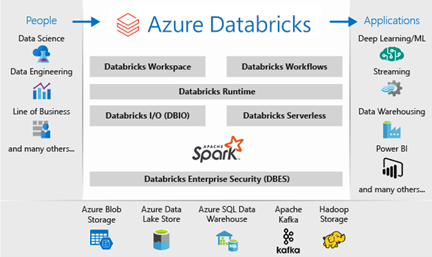
Azure Databricks 中的Spark 生态
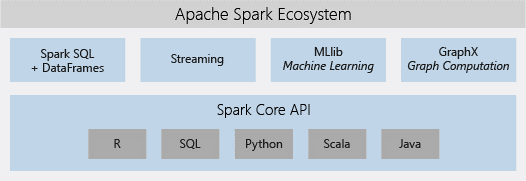
Azure Databricks 包含完整的开源 Apache Spark 群集技术和功能。Azure Databricks 中的 Spark 包括以下组件:
-
Spark SQL 和DataFrames:Spark SQL 是用于处理结构化数据的 Spark 模块。DataFrames是基于列存储的分布式数据集合。它在概念上相当于关系型数据库中的表,或 R/Python 中的DataFrames。
-
流式处理(Streaming):实时数据处理和分析,适用于分析与交互式应用程序。可以与 HDFS、Flume 和 Kafka 集成。
-
MLlib:由常见学习算法和实用工具(包括分类、回归、群集、协作筛选、维数约简以及底层优化基元)组成的机器学习库。
-
GraphX:图形和图形计算,适用于从认知分析到数据探索的广泛用例。
-
Spark Core API:包含对 R、SQL、Python、Scala 和 Java 的支持。
将Azure Databricks应用于企业的关键能力解读
Azure Databricks的架构可以保证跨功能团队的安全协作,同时保留由Azure Databricks管理的大量后端服务,这样使用者就可以专注于数据科学、数据分析和数据工程任务。
尽管架构可能因自定义配置而有所不同 (例如,当Azure Databricks工作区部署到自己的虚拟网络时,也称为VNet注入),下面的架构图表示了Azure Databricks最常见的结构和数据流。
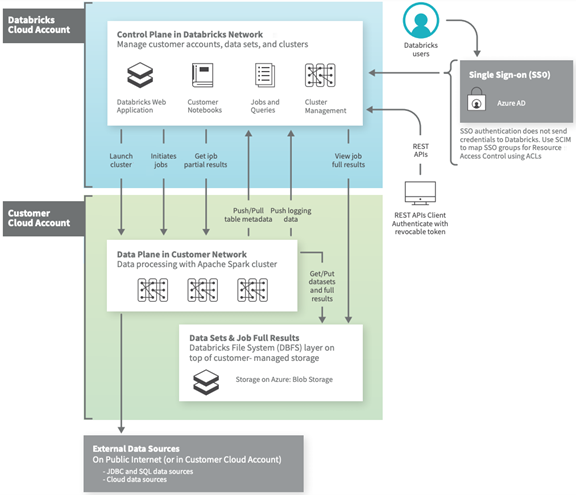
Azure Databricks企业级数据安全设计
控制平面包括Azure Databricks在其自身的Azure帐户中管理的后端服务。用户运行的任何命令都将存在于控制平面中,而用户的代码将完全加密。保存的命令驻留在数据平面中。
数据平面由用户的Azure帐户管理,它是用户数据驻留的地方。这也是处理数据的地方。此图假设数据已经被摄入到Azure数据库中,但是用户可以从外部数据源摄入数据,例如事件(Event)数据、流(Streaming)数据、物联网(IoT)数据等等。用户也可以使用Azure Databricks连接器连接到Azure帐户之外的外部数据源进行存储。
用户的数据总是驻留在数据平面的Azure帐户中,而不是控制平面,因此用户总是保持对数据的完全控制和所有权,而不需要锁定。
Azure Databricks典型数据分析应用场景
在微软云Azure中进行大数据分析时,原始或结构化的数据将通过 Azure 数据工厂以批量的形式引入 Azure,或者通过 Apache Kafka、事件中心(Event Hub)或 IoT 中心进行准实时的流式传输。这些数据摄入模式将数据将驻留在数据湖(Data Lake)的各种存储位置中。在运行分析工作流时,用户可以使用 Azure Databricks 从数据湖的各种数据源读取数据,并使用 Spark 将数据进行处理,再将之放入Azure Cosmos DB,Azure SQL,Azure DB for MySQL或 Azure SQL 数据仓库等服务中,以便于被下游各种数据消费者消费。参考架构如下图所示。
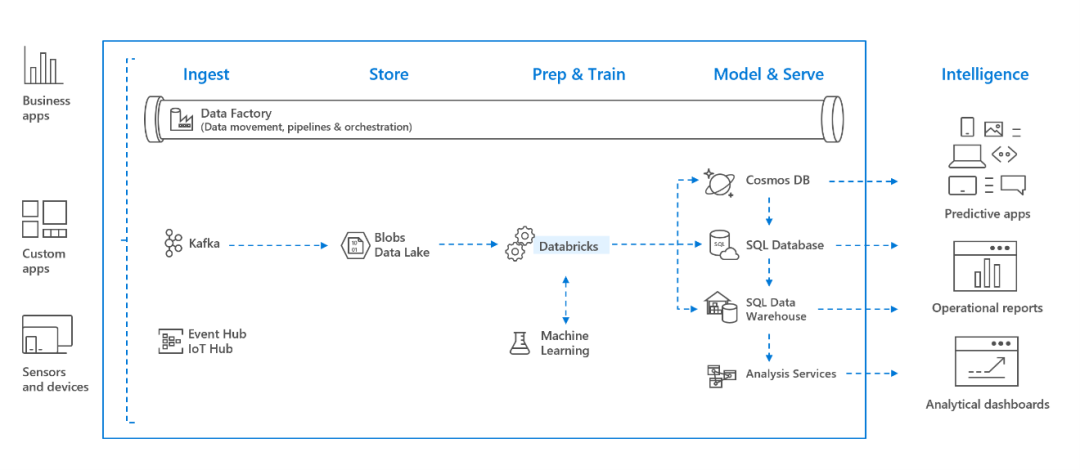
Azure Databricks能力清单
Azure Databricks 拥有一个安全的云上高可用生产环境,由 Spark 专家进行管理和提供支持。用户可以:
-
在几秒钟内创建群集。
-
动态自动扩展和缩减群集并在团队中共享群集。
-
通过调用 REST API 以编程方式使用群集。
-
使用基于 Spark 的安全数据集成功能,在不用集中化的情况下统一数据。
-
及时获得每个版本中的最新 Apache Spark 功能。
Azure Databricks 工作区(Workspace)
构建在完整的 Spark 功能基础之上,提供一个完全托管的云平台,其中包括:
-
完全托管的 Spark 群集
-
用于探索和可视化的交互式工作区
-
一个为现有的Spark应用程序提供支持的平台
Databricks 运行时(Runtime)
-
Azure Databricks 运行时构建在 Apache Spark 的基础之上,是Spark 创始团队专门针对 Azure 云以原生方式构建和优化的的。
-
Azure Databricks 通过高度抽象化彻底消除了基础结构复杂性,无需专业知识就能设置和配置大数据分析基础设施。
-
对于性能敏感的生产作业而言,Azure Databricks 通过 I/O 层和处理层 (Databricks I/O) 的各种优化提供了一个优于开源版本20-50倍的 Spark 引擎。
云上大数据协同分析
-
通过协作和集成式环境,Azure Databricks 简化了在 Spark 中浏览数据、制作原型和运行数据驱动型应用程序的过程。
-
通过简单的数据浏览确定如何使用数据。
-
在以 R、Python、Scala 或 SQL 编写的笔记本中记录进度。
-
几步内即可实现数据可视化,可以使用熟悉的工具,例如 Matplotlib、ggplot 或 d3。
-
使用交互式仪表板创建动态报告。
-
在使用 Spark 的同时与数据交互。
转载地址:http://tnrtf.baihongyu.com/